

Preparación de datos con AWS Glue DataBrew
AWS Glue DataBrew es una herramienta de preparación visual que permite que tanto analistas como científicos de datos puedan limpiar y normalizar data de una manera mucho más fácil, con la finalidad de prepararla para procesos de análisis y machine learning, todo sin la necesidad de escribir código.
Con AWS Glue DataBrew se puede automatizar el filtrado de anomalías en los datos, corregir valores o convertirlos a formatos estándar que nosotros necesitemos. El servicio provee una interfaz visual que permite conectarse rápidamente a datos almacenados en Amazon S3, Amazon Redshift, Amazon RDS, cualquier almacenamiento accesible por JDBC o data indexada en AWS Glue Data Catalog.
Una vez los datos ya están listos, estos pueden ser utilizados inmediatamente por otros servicios de AWS como Amazon SageMaker (para machine learning), Amazon Redshift y Amazon Athena (para análitica), o Amazon Quicksight y Tableau (para Business Intelligence).
Iniciando un proyecto con AWS Glue DataBrew
Para empezar a trabajar con AWS Glue DataBrew, buscaremos primero el servicio en la consola, y luego haremos click sobre la opción de Crear proyecto de muestra.
Nos aparecerá una ventana de configuración, donde haremos lo siguiente:
- Seleccionar conjunto de datos de muestra: de las opciones mostradas, seleccionaremos la que dice Datos de descubrimiento de fármacos de ChEMBL.
- Nombre del rol: seleccionaremos la opción de Crear un nuevo rol de IAM.
- Nuevo sufijo del rol de IAM: proyecto-de-muestra
- Finalmente, hacemos click donde dice Crear proyecto
Nos aparecerá una ventana como la siguiente, donde esperaremos a que la sesión se cargue.

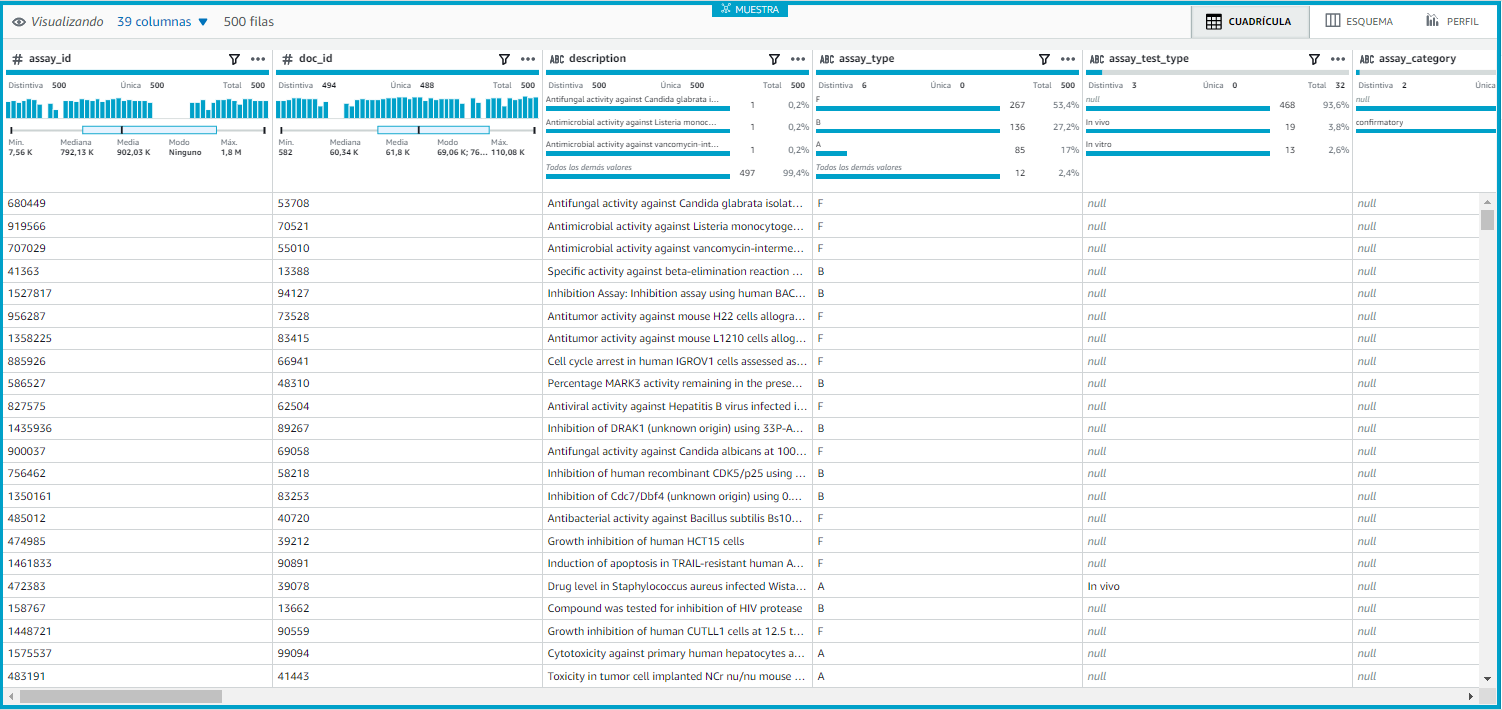
Cuando se cargue la sesión, veremos una muestra de los datos en la interfaz, donde podremos ver el nombre de cada columna, datos informativos de cada una (como la mediana, el valor mínimo y el máximo en datos del tipo numérico) y podremos empezar a generar nuestra receta.
¿Qué es la receta?
La receta es la serie de pasos de transformación que el usuario define para los datos en el proyecto. Utilizando las herramientas de DataBrew, podremos visualizar el efecto de cada paso en el dataset hasta llegar al resultado final deseado.
En la parte superior de la tabla con el dataset, podemos ver todas el menú general de transformación que tenemos disponible. Al hacer click sobre cada una de las opciones en el menú, podremos ver el listado de funciones que contienen. Con estas herramientas podemos filtrar, cambiar nombres de columnas, eliminar caracteres especiales, mapear, codificar, y muchas acciones más, acorde a las necesidades que tengamos.
Al explorar el dataset de muestra, podremos ver que tiene 39 columnas en total. Para este ejercicio, supondremos que las transformaciones requeridas son las siguientes:
- Eliminar la columna tid_fixed pues todos los valores son null
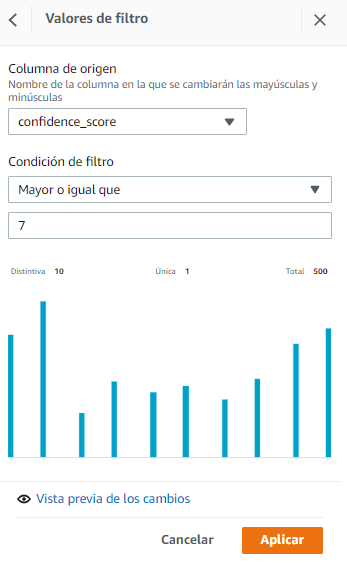
- Dejar únicamente las filas que tengan un confidence_score mayor o igual a 7
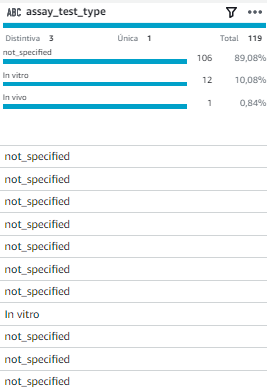
- Para la columna assay_test_type, cambiar los valores null por “not_specified”
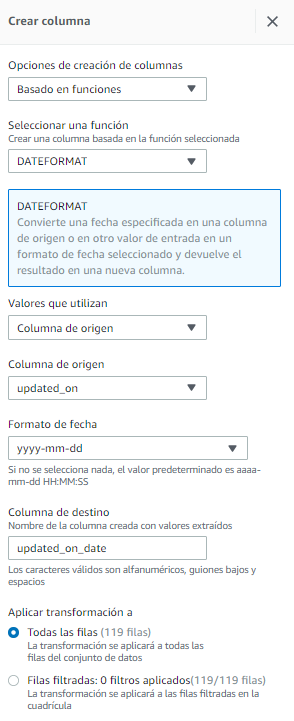
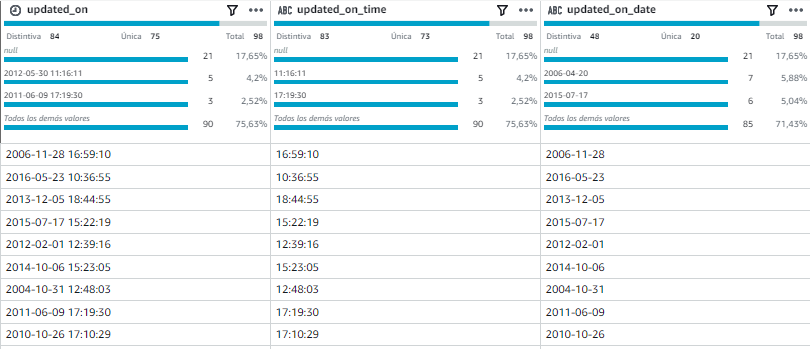
- Separar la columna updated_on en dos que sean updated_on_date y updated_on_time
- Convertir todos los datos de la columna mc_target_type a letras minúsculas
Ahora, veremos cómo llevar a cabo cada uno de estos pasos utilizando las herramientas de DataBrew.
Paso 1 – Eliminar la columna tid_fixed
Haremos click sobre 

Veremos que ahora dicho paso está enlistado en nuestra receta.

Paso 2 – Dejar únicamente las filas que tengan un confidence_score mayor o igual a 7
Aquí haremos click sobre 
Paso 3 – Para la columna assay_test_type, cambiar los valores null por “not_specified”
Para este paso hacemos click en 
Veremos que en los valores null han sido cambiados a not_specified.
Paso 4 – Separar la columna updated_on en dos que sean updated_on_date y updated_on_time
Para este paso, hacemos click en 
Para generar la columna de updated_on_time repetimos los pasos anteriores, pero cambiando lo siguiente:
- Formato de fecha: ISO HH:MM:SS
- Columna de destino: updated_on_time
Como resultado tendremos agregadas a nuestro dataset las dos columnas deseadas.
Paso 5 – Convertir todos los datos de la columna mc_target_type a letras minúsculas
Para este paso, haremos click sobre 
Después de este último paso, tendremos la receta completa de nuestra transformación. Ahora procederemos a publicarla.
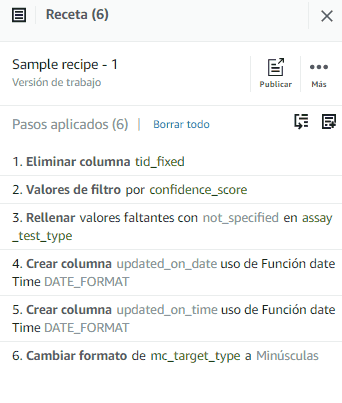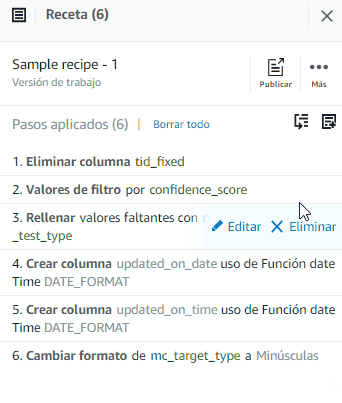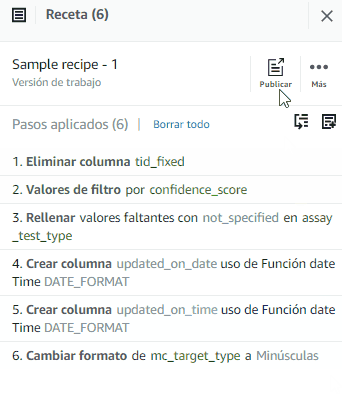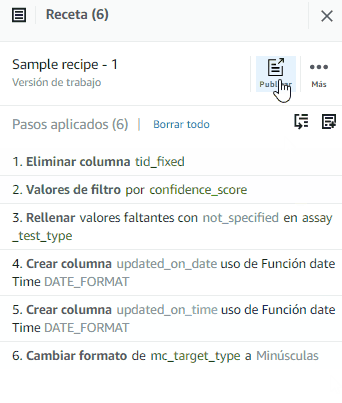
En Descripción de la versión escribimos “Probando DataBrew” y hacemos click en Publicar.
Ahora ya tenemos nuestra receta guardada, y podemos crear un trabajo para ejecutar esos pasos en el dataset completo, puesto que todo lo anterior se hizo sobre una muestra de los datos, solo para poder visualizar el resultado de cada paso de transformación.
Creando un trabajo
De vuelta en la consola de Glue, debemos buscar la opción de Trabajos en el menú izquierdo, y luego en Trabajos de recetas debemos hacer click sobre Crear trabajo.
En los detalles del trabajo, llenaremos las casillas de la siguiente manera:
- Nombre del trabajo: sample-chembl-job
- Tipo de trabajo: Crear trabajo de receta
- Ejecutar en: Conjunto de datos
- Seleccionar un conjunto de datos: chembl-27
- Seleccionar una receta: Sample recipe – 1 (o el nombre bajo el cual hayamos guardado nuestra receta)
- Salida a: Amazon S3
- Tipo de archivo: CSV
- Delimitador: Coma (,)
- Compresión: None
- Ubicación de Amazon S3: Elegimos un bucket y folder para nuestra salida
- Nombre del rol: Elegimos el rol creado al inicio, AWSGlueDataBrewServiceRole-proyecto-de-muestra
- Dejamos el resto de configuraciones por defecto, y hacemos click en Crear y ejecutar trabajo.
Nuestro trabajo se creará y empezará a ejecutarse.
Esperamos un poco, un par de minutos para este conjunto de datos, y veremos que el mensaje cambia a Realizado con éxito. Podemos hacer click sobre Salida, y nos aparecerá una ventana con la ubicación de S3 de nuestros datos resultantes, haremos click sobre la ubicación en S3, y este nos redirigirá al archivo csv. Si lo descargamos y lo abrimos, veremos el conjunto de datos final con todos los pasos de nuestra receta aplicados.

Conclusiones
Este ejemplo es una muestra sencilla de lo que puede hacerse con AWS Glue DataBrew, su facilidad de uso y cómo puede agilizar el proceso de preparación de los datos para analistas y científicos a partir de su interfaz visual, proveyendo inclusive la previsualización de las transformaciones, lo que puede ser de gran utilidad sobre todo al manejar recetas más complejas que lleven muchos más pasos.
Autor: Andrea Monzón
