

Google BigQuery se lanzó para disponibilidad general en 2011 y es el almacén de datos empresariales de Google Cloud diseñado para la agilidad empresarial. Su arquitectura Serverless le permite operar a escala y velocidad para proporcionar análisis SQL increíblemente rápidos en grandes conjuntos de datos.
¿Cómo impulsa un almacén de datos las decisiones comerciales?
Un almacén de datos consolida datos de fuentes dispares y realiza análisis de los datos agregados para agregar valor a las operaciones comerciales al proporcionar información. Los almacenes de datos son los custodios de los datos comerciales más importantes de la empresa durante las últimas dos décadas. A medida que las empresas se vuelven cada vez más impulsadas por los datos, los almacenes de datos desempeñan un papel cada vez más crítico en su proceso de transformación digital. Hoy en día, las empresas necesitan:
- Tener una vista de 360⁰ de sus negocios: los datos son valiosos. A medida que se reducen los costos de almacenamiento y procesamiento de datos, las empresas desean procesar, almacenar y analizar todos los conjuntos de datos relevantes, tanto internos como externos a su organización.
- Sea consciente de la situación y responda a los eventos comerciales en tiempo real: las empresas necesitan obtener información de los eventos en tiempo real y no esperar días o semanas para analizar los datos. El almacén de datos debe reflejar el estado actual del negocio en todo momento.
- Reduce el tiempo de obtención de información: las empresas necesitan ponerse en marcha rápidamente sin tener que esperar días o meses para que el hardware o el software se instalen o configuren.
- Ponga los conocimientos a disposición de los usuarios comerciales para permitir la toma de decisiones basada en datos en toda la empresa: para adoptar una cultura basada en datos, las empresas deben democratizar el acceso a los datos.
- Asegure sus datos y gobierne su uso: los datos deben estar seguros y accesibles para las partes interesadas correctas dentro y fuera de la empresa.
¿Dónde encaja BigQuery en el ciclo de vida de los datos?
BigQuery es parte de la plataforma integral de análisis de datos de Google Cloud que cubre toda la cadena de valor de análisis, incluida la ingesta, el procesamiento y el almacenamiento de datos, seguidos de análisis y colaboración avanzados. BigQuery está profundamente integrado con las ofertas de análisis y procesamiento de datos de GCP, lo que permite a los clientes configurar un almacén de datos nativo de la nube listo para la empresa.
En cada etapa del ciclo de vida de los datos, GCP proporciona múltiples servicios para administrar los datos. Esto significa que los clientes pueden seleccionar un conjunto de servicios adaptados a sus datos y flujo de trabajo.
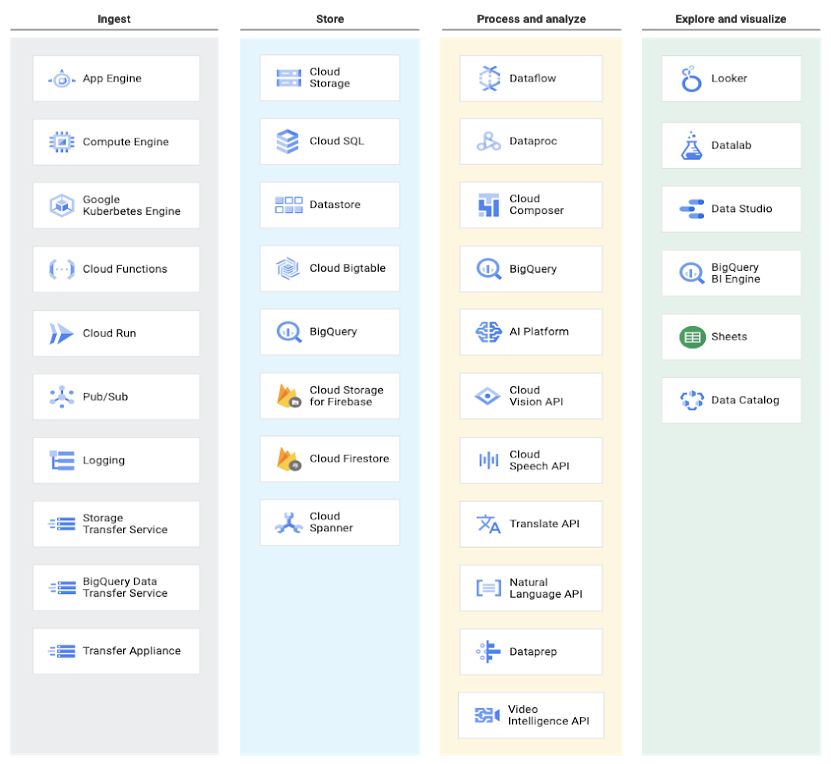
Ingerir datos en BigQuery
BigQuery admite varias formas de ingerir datos en su almacenamiento administrado. El método de ingesta específico depende del origen de los datos. Por ejemplo, algunas fuentes de datos en GCP, como Cloud Logging y Google Analytics, admiten exportaciones directas a BigQuery.
El Servicio de transferencia de datos de BigQuery permite la transferencia de datos a BigQuery desde las aplicaciones SaaS de Google (Google Ads, Cloud Storage), Amazon S3 y otros almacenes de datos (Teradata, Redshift).
Los datos de transmisión, como registros o datos de dispositivos IoT, se pueden escribir en BigQuery mediante canalizaciones de Cloud Dataflow , trabajos de Cloud Dataproc o directamente mediante la API de ingesta de transmisión de BigQuery .
Arquitectura de BigQuery
La arquitectura sin servidor de BigQuery desvincula el almacenamiento y la computación y te permite escalar de forma independiente según la demanda. Esta estructura ofrece una inmensa flexibilidad y controles de costos para los clientes porque no necesitan mantener sus costosos recursos informáticos en funcionamiento todo el tiempo.
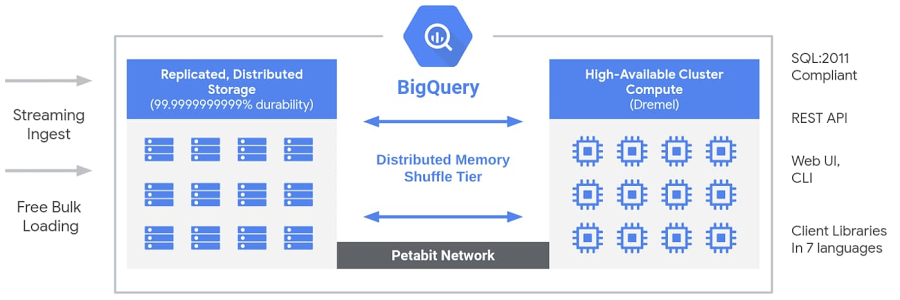
Debajo del capó, BigQuery emplea un amplio conjunto de servicios multiusuario impulsados por tecnologías de infraestructura de Google de bajo nivel como Dremel, Colossus, Jupiter y Borg .
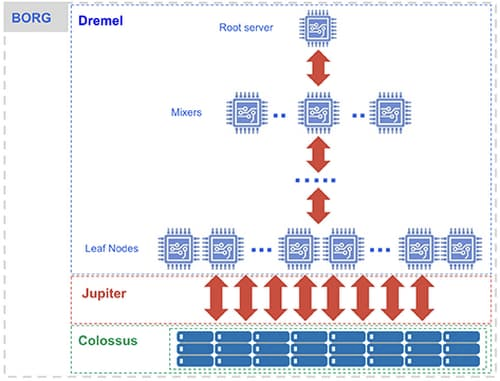
Compute es Dremel , un gran clúster de múltiples inquilinos que ejecuta consultas SQL.
- Dremel convierte las consultas SQL en árboles de ejecución. Las hojas del árbol se llaman ranuras y hacen el trabajo pesado de leer datos del almacenamiento y cualquier cálculo necesario. Las ramas del árbol son ‘mezcladores’, que realizan la agregación.
- Dremel asigna ranuras dinámicamente a las consultas según sea necesario, manteniendo la equidad para las consultas simultáneas de varios usuarios. Un solo usuario puede obtener miles de espacios para ejecutar sus consultas.
El almacenamiento es Colossus , el sistema de almacenamiento global de Google.
- BigQuery aprovecha el formato de almacenamiento en columnas y el algoritmo de compresión para almacenar datos en Colossus, optimizado para leer grandes cantidades de datos estructurados.
- Colossus también maneja la replicación, la recuperación (cuando los discos fallan) y la administración distribuida (por lo que no hay un punto único de falla). Colossus permite a los usuarios de BigQuery escalar a docenas de petabytes de datos almacenados sin problemas, sin pagar la penalización de adjuntar recursos informáticos mucho más costosos como en los almacenes de datos tradicionales.
La computación y el almacenamiento se comunican entre sí a través de la red petabit deJúpiter .
- Entre el almacenamiento y la computación se encuentra la ‘reproducción aleatoria’, que aprovecha la red Júpiter de Google para mover datos extremadamente rápido de un lugar a otro.
BigQuery está orquestado a través deBorg , el precursor de Google de Kubernetes .
- Los mezcladores y las ranuras están a cargo de Borg, que asigna los recursos de hardware.
¿Cómo puedes empezar con BigQuery?
Puede comenzar a usar BigQuery simplemente cargando datos y ejecutando comandos SQL. No es necesario crear, implementar o aprovisionar clústeres; no es necesario dimensionar las máquinas virtuales, el almacenamiento o los recursos de hardware; no es necesario configurar discos, definir la replicación, configurar la compresión y el cifrado, o cualquier otro trabajo de instalación o configuración necesario para construir un almacén de datos tradicional.
En Criptonube te apoyamos en la implementación de BigQuery en Google Cloud para tu negocio.
Para más información da clic AQUÍ

Autor:
Oscar Dieguez – Técnico de Google en Criptonube
