

Una de las principales cosas que se recomiendan al comenzar a trabajar en la nube es AUTOMATIZAR, pero comenzar este proceso puede ser un recorrido del cual no sabemos dónde comenzar. En este blog se propone que comencemos con lo que todo ambiente debe de tener en cuenta, BACKUPS, para eso usaremos la api de 2 servicios, EVS y IMS .
Antes de seguir adelante asegurarse de cumplir con los siguientes requerimientos
- Crear una AGENCIA primero a la cual le debemos dar permisos de administración de EVS e IMS.
- Tener a la mano la documentación de la API tanto de EVS como de IMS.
- Conocimiento de Python
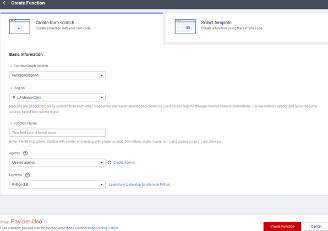
Como primera fase tendremos que agregar las librerías que necesitamos y configuraremos variables, al menos las siguientes para poder crear ya sea el snapshot o la imagen, en este caso será el snapshoot.
| # -*- coding:utf-8 -*- import time import sys import requests import json from threading import Thread from datetime import datetime, timedelta def handler(event, context): projectId = context.getUserData(“projectId”, “”).strip() region = context.getUserData(“region”, “”).strip() volumeIds = context.getUserData(“volumeIds”, “”).strip().split(“,”) volumeNames = context.getUserData(“volumeNames”, “”).strip().split(“,”) retentionPeriod = context.getUserData(“retentionPeriod”, “”).strip() logger = context.getLogger() token = context.getToken() snapshotUrl = f”https://evs.{region}.myhuaweicloud.com/v2/{projectId}/snapshots” _create_snapshots(logger, token, volumeIds, volumeNames, snapshotUrl) |
Ahora a la función que deseo que cree los snapshots
para no tener que crear una función por cada disco, es que se maneja todo como strings de datos. para los snapshots es simple ya que solo tenemos un tipo de snapshoot.
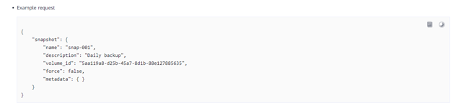
Pero en el caso de las imágenes debemos recordar que tenemos system disk y data disk images, y aparte full ecs images.
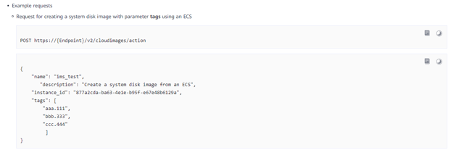
En la documentación hay ejemplos de cada una de estos tipos.
En la primera función se encarga de ordenar cada uno de los valores de las variables de estado y luego las usamos en _create_snapshot como la API en su documentación lo muestra.
| def _create_snapshots(logger, token, volumeIds, volumeNames, snapshotUrl): threads = [] for volumeNum in range(len(volumeIds)): t = Thread(target=_create_snapshot,args=(logger, token, volumeIds[volumeNum], volumeNames[volumeNum], snapshotUrl)) t.start() threads.append(t) if not threads: logger.info(“no snapshot(s) to create.”) return 0 logger.info(f”{len(threads)} snapshot(s) will be created.”) for t in threads: t.join() def _create_snapshot(logger, token, volumeId, volumeName, snapshotUrl): now = datetime.now().strftime(“%Y-%m-%d-%H:%M:%S”) snapshotName = f”{volumeName}-{now}” authHeader = {“X-Auth-Token”: token, “Content-Type” : “application/json”} snapshotRequestBody = { “snapshot”: { “name”: snapshotName, “volume_id”: volumeId, “force”: True } } snapshotRequest = requests.post( snapshotUrl, data=json.dumps(snapshotRequestBody), headers=authHeader ) statusCode = snapshotRequest.status_code if statusCode == 202: logger.info(f”Snapshot {snapshotName} created successfully.”) return 0 else: logger.info(f”Snapshot {snapshotName} wasn’t able to be created.”) logger.info(json.dumps(snapshotRequest.json())) return 2 |
Claro que podemos crear una función para eliminar o quizás manejar diferentes funciones por disco o podríamos en una misma función con diferentes DEF hacer todo.
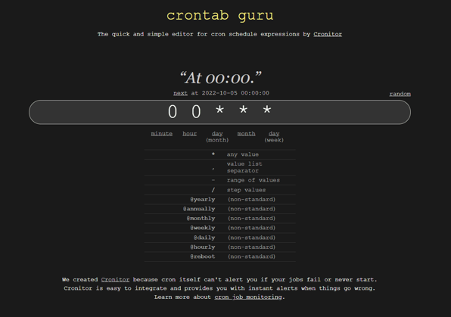
Lo siguiente es configurar un trigger para la función.
la recomendación del blog será hacer una simple cron expressions
De necesitar apoyo haciendo tu propia función, no dudes en contactarnos clic AQUÍ

AUTOR: Juan Rafael Roque
